当企业拥抱AI智能体,开启“人人都有AI助手”的时代,你是否意识到,这背后隐藏着一场算力供给与成本控制的激烈博弈?在Clawdbot(moltbot)、Manus、OpenCode等智能体应用迅速推广的背景下,一场围绕大模型推理优化的技术革命悄然进行。从模型压缩到架构创新,从存储优化到一体化部署,行业正在努力突破LLM算力瓶颈。
开普云正通过软硬件协同创新,系统性地解决大模型推理中的计算效率与存储瓶颈,推动AI应用从实验室走向规模化落地。
当前LLM推理面临两大核心挑战:计算效率瓶颈与AI存储压力。
在计算角度方面
大模型推理一般由Prefill和Decode两阶段构成。Prefill阶段是计算密集型,对算力需求高;Decode阶段是存储密集型,对显存需求高。传统方式通常将两阶段部署在同一节点,导致资源争夺、并行策略互相掣肘,进一步造成资源利用率低、服务性能差等问题。
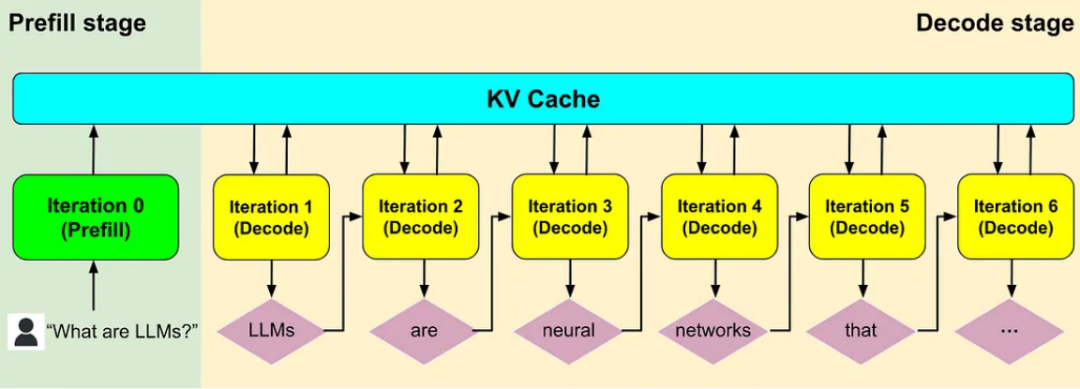
图 1 大模型Prefill和Decode示意图
在AI存储方面
KV Cache成为推理算力提升的关键技术瓶颈。随着大模型超长上下文扩展至128K甚至百万级token数,KV Cache消耗显存资源线性增长,导致显存带宽压力增大、延迟上升,KV Cache的存储效能成为智算技术突破的另一瓶颈。
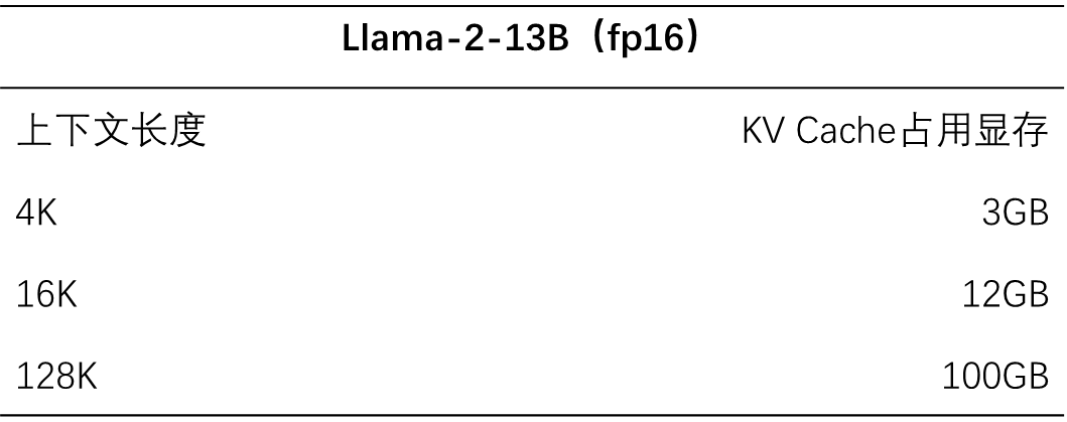
图 2 Llama-2-13B中 KV Cache占用显存随上下文长度线性变化
面对上述挑战,开普云从模型量化、分级缓存、自动算子生成三个方向展开了系统性研究,构建了完整的智能体算力优化技术体系,实现了模型层、系统层和硬件层的深度协同优化。
在模型轻量化方面
量化技术采用低比特表示来压缩模型大小,可显著降低对存储和计算资源的需求。开普云在推理引擎层面实现了FP8与FP4的混合精度推理,并结合SmoothQuant等算法,在保持精度的同时显著降低了计算与存储成本。FP8相较于INT8,数值表示范围扩大3.5倍,小数精细度提升500倍,有效避免了因量化或蒸馏过程导致的错误幻觉,确保模型输出结果的高精度与可靠性。通过与DeepSeek等国产大模型厂商、华为等国产算力硬件厂商的深度合作,开普云实现了量化版DeepSeek系列模型对昇腾910B芯片国产芯片的完美适配。
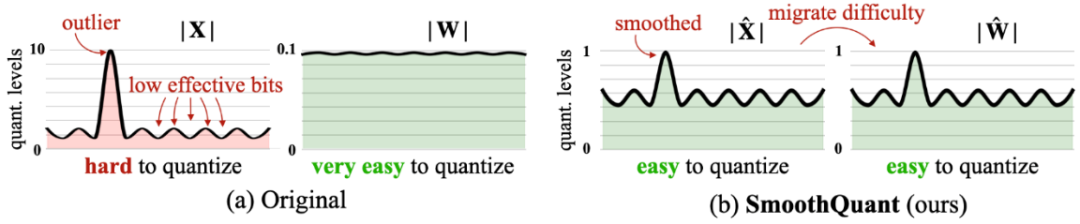
图 3 SmoothQuant对激活和权重进行不同的量化
在AI存储方面
KV Cache多层存储技术通过分离计算和存储,解决显存资源过度占用的问题,提升服务吞吐性能,并支持更长的上下文处理。针对超长上下文推理场景,开普云提出了“显存—内存—SSD”的三层分级KV Cache调度机制。系统会动态预测缓存热度,把不常用的数据迁移到低速介质中,从而在不牺牲性能的前提下,显著扩大上下文长度。在测试中,128K tokens超长上下文推理任务的吞吐性能提升了1.5倍,使得长文档分析、对话历史记忆等任务在国产芯片上顺畅运行。
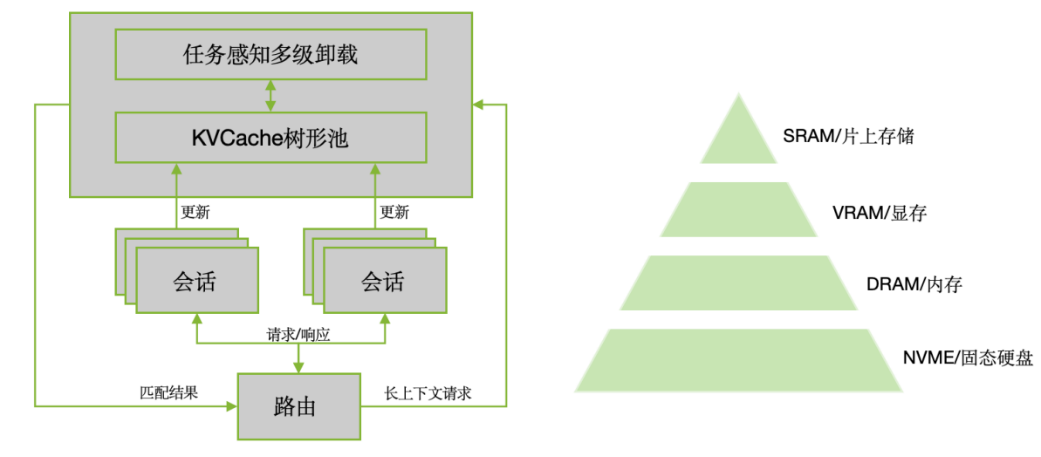
图 4 KV Cache分层存储管理示意图
在硬件适配方面
硬件层缺少适配算子,将会导致算力利用率远低于理论峰值。开普云结合Codegen工具与国产编译器,完成了算子的自动生成与流水线调度。让芯片根据自身特性自动生成最优矩阵计算内核。经过大量调优,开普云的算子执行效率可达95%以上,在赶超国际主流GPU的性能方面差距显著缩小。
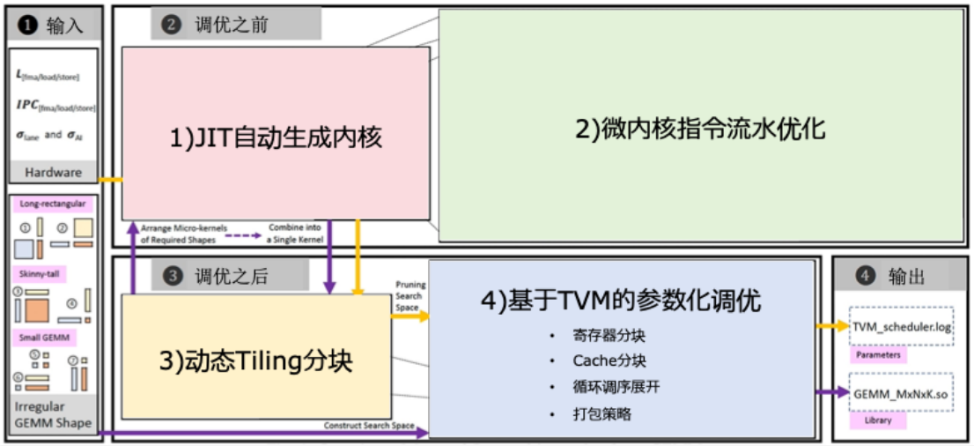
图 5 硬件感知的算子自动生成示意图
开普云通过低精度优化、分级缓存技术和自动算子生成等技术协同优化,成功解决了大模型推理中的显存限制、计算效率低和国产芯片适配不足等难题。基于上述技术优化路径,公司构建了完整的智能体一体机产品矩阵,覆盖从单机到集群的全栈式智能体算力解决方案。

图 6 “开悟智核”智能体一体机
产品矩阵与差异化定位
开普云推出“开悟智核”智能体一体机多版本产品矩阵,涵盖五大版本,层层递进,全面覆盖各类企业场景:
基础型号“开悟智核”以极致性价比满足中小团队需求;开悟智核Plus,采用KTransformers深度优化推理框架,通过内存压缩及动态显存分配技术,实现推理速度更快,显存占用更低,可满足百人团队效率提升需求;开悟智核Pro注重信创安全,服务于百人规模组织,提供智能问答、公文写作及数据分析等办公辅助功能;开悟智核Pro+,主打高性能计算能力,同样配备智能体应用快速搭建和一站式AI部署,在确保与公网版DeepSeek相当体验的同时,为企业数据安全提供可靠保障;而旗舰型号“开悟智核Pro Max”则具备业界领先的单机推理性能,总吞吐量达3000+tokens/s,能为千人以上大型组织提供强劲、安全的AI算力支撑。
产品核心优势
开普云智能体一体机具有五大核心优势:
硬件适配:全系支持国产芯片(如昇腾910B),满足关键领域对国产化的要求。
算力效率:通过低精度优化和分级缓存技术,降低显存占用60%-80%,支持128K tokens超长上下文推理,总吞吐量超300 token/s,优于开源社区基准。