来源 :中国证券网2025-03-24
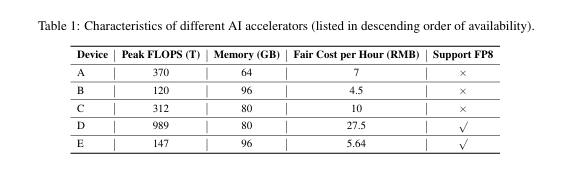
近日,蚂蚁集团Ling团队发表了一篇技术成果论文。论文显示,蚂蚁集团推出两款不同规模的MoE大语言模型――百灵轻量版(Ling-Lite)与百灵增强版(Ling-Plus),前者参数规模为168亿(激活参数27.5亿),后者参数规模高达2900亿(激活参数288亿),两者性能均达到行业领先水平。

在论文中,Ling团队重点探讨了训练大规模专家混合模型(MoE)所面临的挑战,尤其是此类系统中普遍存在的成本效率低下和资源限制问题。为解决此类问题,团队推出百灵轻量版与百灵增强版模型。
据介绍,论文提出的方法可以提高在资源有限的环境中开发人工智能的效率和可及性(accessibility),并推广更具可推广性和可持续性的技术。
有业内人士表示,MoE模型的训练通常依赖于高性能计算资源(如H100和H800等AI加速卡),如此高的成本不利于训练在资源有限的环境中实现广泛应用。
与之相对的是,为了降低大规模MoE模型的训练成本,论文提出了若干创新方法,包括优化模型架构和训练流程;改进训练异常处理;提高模型评估效率。此外,利用知识图谱生成高质量数据,模型在工具使用方面表现出与其他模型相比更为卓越的能力。
实验结果表明,300B MoE LLM可以在较低性能的设备上进行有效训练,同时获得与类似规模模型(包括dense模型和MoE模型)相当的性能。此外,模型在预训练阶段使用较低规格的硬件系统可显著节约成本,与高性能设备相比,其计算成本可降低约20%。
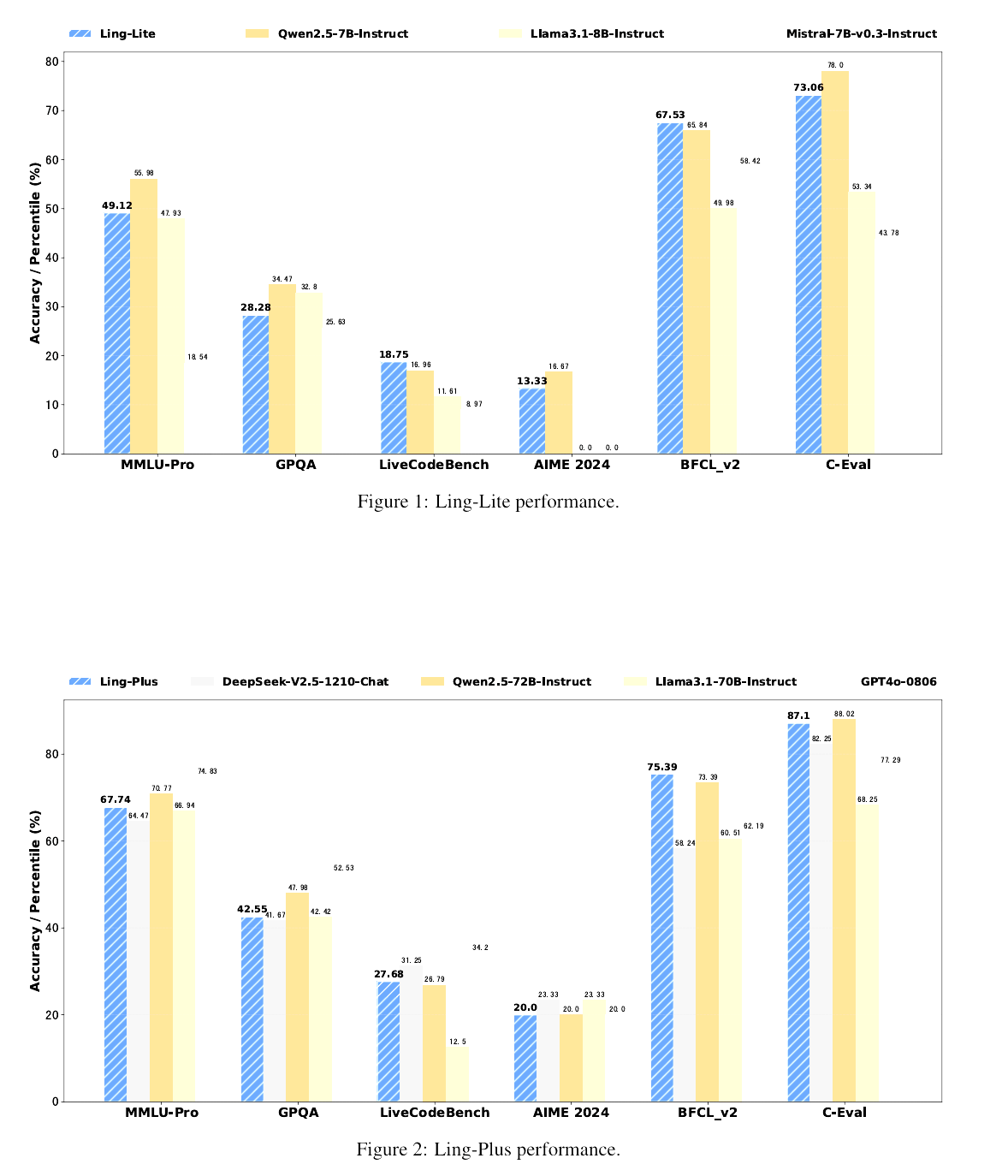
Ling团队声称,开源的百灵系列MoE模型实现了资源成本与模型性能之间的平衡。在算力较小的硬件上训练SOTA级别的MoE大模型是可行的,从而在计算资源选择方面为基础模型的开发提供了一种更灵活、更具成本效益的方法。
值得注意的是,模型开发使用的语料库是一个文本和非文本数据的多样化集合,包括网络内容、书籍、学术论文、社交媒体、百科全书、数学和程序代码等。而这一高质量的语料库内含约9万亿个token,包括1万亿个中文token、5.5万亿个英文token和2.5万亿个代码token。